
这篇文章的标题有点绕口,但确实是在计算因子时遇到的一种实际场景。例如,我们找到了前期高点的位置,然后想要统计前期高点位置之前的10个交易日内出现涨停的次数。
问题描述
我们以sh.603906龙蟠科技为例,相关数据保存在DataFrame类型的对象df中,以下显示2021年9月9日至2021年9月24日之间10个交易日的数据:
date open high low ... isST zt xg qg_jl
1080 2021-09-09 40.00 40.36 38.06 ... 0 False False 19
1081 2021-09-10 38.79 40.00 38.30 ... 0 False False 20
1082 2021-09-13 41.00 43.76 39.91 ... 0 True False 21
1083 2021-09-14 44.68 46.80 42.92 ... 0 False False 22
1084 2021-09-15 45.70 49.96 44.00 ... 0 True True 23
1085 2021-09-16 52.31 53.46 45.87 ... 0 False True 1
1086 2021-09-17 46.20 46.73 44.00 ... 0 False False 1
1087 2021-09-22 45.03 46.37 43.50 ... 0 False False 2
1088 2021-09-23 45.18 48.73 43.92 ... 0 True False 3
1089 2021-09-24 48.65 53.60 47.10 ... 0 False True 4
其中,zt列表示当日是否涨停,xg列表示是否为120日来的新高点,qg_jl列表示与前期高点间的距离。
对应看一下K先图:
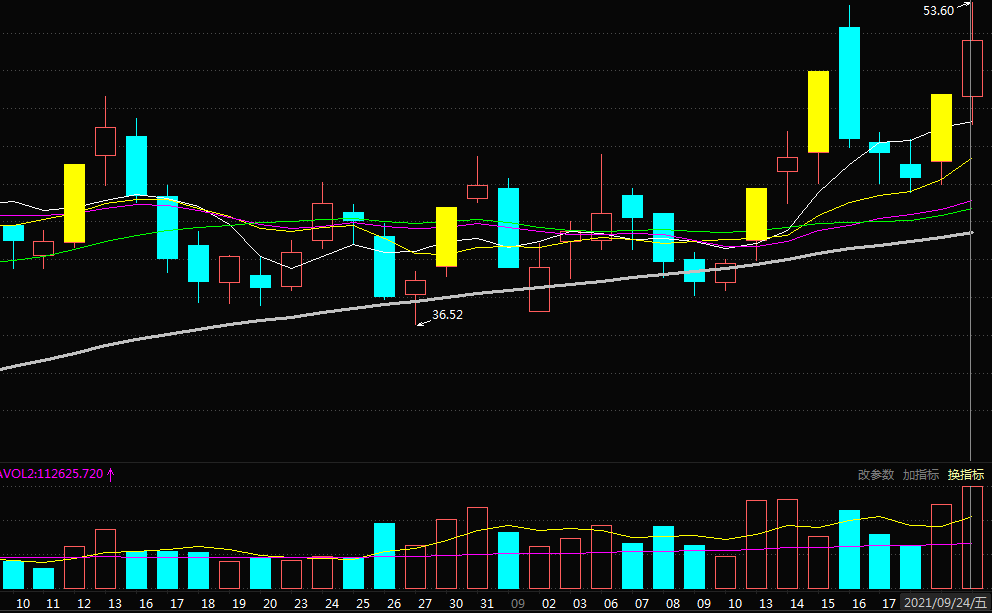
- 9月15日,涨停,因此zt列的值为True;形成120日新高,因此xg列的值为True;前高的日期为8月13日,距离为23,因此qg_jl列的值为23。
- 9月23日,涨停,因此zt列的值为True;未形成120日新高,因此xg列的值为False;前高的日期为9月16日,距离为3,因此qg_jl列的值为3。
- 9月24日,未涨停,因此zt列的值为False;形成120日新高,因此xg列的值为True;前高的日期为9月16日,距离为4,因此qg_jl列的值为4。
为了统计前期高点前的涨停个数,我们对涨停因子进行移动,得到temp_df,部分列显示如下:
date zt_1a zt_2a zt_3a ... zt_127a zt_128a zt_129a zt_130a
1080 2021-09-09 False False False ... False False False False
1081 2021-09-10 False False False ... False False False False
1082 2021-09-13 False False False ... False False False False
1083 2021-09-14 True False False ... False False False False
1084 2021-09-15 False True False ... False False False False
1085 2021-09-16 True False True ... False False False False
1086 2021-09-17 False True False ... False False False False
1087 2021-09-22 False False True ... False False False False
1088 2021-09-23 False False False ... False False False False
1089 2021-09-24 True False False ... False False False False
其中zt_1a表示1天前是否涨停,zt_2a表示2天前是否涨停,以此类推。
我们的目标是统计前期高点位置之前的10个交易日内出现涨停的次数,仍以上面三个交易日为例:
- 9月15日,前高距离qg_jl为23, 统计前期高点之前的10个交易日出现涨停的次数,就等价于统计zt_23a、zt_24a、zt_25a、…、zt_32a中值为True的个数。
- 9月23日,前高距离qg_jl为3,统计前期高点之前的10个交易日出现涨停的次数,就等价于统计zt_3a、zt_4a、zt_5a、…、zt_12a中值为True的个数。
- 9月24日,前高距离qg_jl为4,统计前期高点之前的10个交易日出现涨停的次数,就等价于统计zt_4a、zt_5a、zt_6a、…、zt_13a中值为True的个数。
可以看出,我们的问题转化为了根据列qg_jl的值,来获取不同的zt_Xa列的值,也就是本文题目中所描述的问题。
解决方案
先上代码:
qg_day = 10
for i in range(qg_day):
temp_df['temp_name_zt_{}'.format(i)] = temp_df['qg_jl'].apply(lambda x: 'zt_{}a'.format(int(x + i)))
temp_df['qg_zt_{}'.format(i)] = None
for val in temp_df['temp_name_zt_{}'.format(i)].unique():
temp_df.loc[temp_df['temp_name_zt_{}'.format(i)] == val, 'qg_zt_{}'.format(i)] = temp_df[val]
cols = ['qg_zt_{}'.format(x) for x in range(qg_day)]
df['qg_zt_num'] = temp_df[cols][temp_df[cols]].count(1)
- 第1行,定义变量qg_day,用于设置访问前期高点前多少天的数据,我们这里统计前期高点之前的10个交易日出现涨停的次数,所以赋值为10。
- 2~6行,循环构造列,用于后续统计选择时间范围内的涨停次数。
- 第3行,构造新列temp_name_zt_X,用于存放待统计涨停列的列名,打印结果如下:
date temp_name_zt_0 ... temp_name_zt_8 temp_name_zt_9
1080 2021-09-09 zt_19a ... zt_27a zt_28a
1081 2021-09-10 zt_20a ... zt_28a zt_29a
1082 2021-09-13 zt_21a ... zt_29a zt_30a
1083 2021-09-14 zt_22a ... zt_30a zt_31a
1084 2021-09-15 zt_23a ... zt_31a zt_32a
1085 2021-09-16 zt_1a ... zt_9a zt_10a
1086 2021-09-17 zt_1a ... zt_9a zt_10a
1087 2021-09-22 zt_2a ... zt_10a zt_11a
1088 2021-09-23 zt_3a ... zt_11a zt_12a
1089 2021-09-24 zt_4a ... zt_12a zt_13a
9月15日,需要访问其zt_23a至zt_31a,9月23日,需要访问zt_3a至zt_12a,9月24日,需要访问zt_4a至zt_13a,与问题描述中分析结果一致。
- 第4行,构建新列qg_zt_X,值都置为None。
-
5~6行,循环对qg_zt_X列赋值,以i=0时为例,即使用temp_name_zt_0列给qg_zt_0列赋值。当循环到val=zt_1a时,
temp_df.loc[temp_df['temp_name_zt_{}'.format(i)] == val, 'qg_zt_{}'.format(i)]就将temp_name_zt_0列中值为zt_1a的行都筛选出来,上面打印的10个交易日数据来说,9月16日和17日temp_name_zt_0列的值均为zt_1a,这两行就会被筛选出来。然后temp_df[val]会把列zt_1a提取出来,对前面得到的temp_name_zt_0列值为zt_1a的行的qg_zt_0列赋值(有点绕,可以看后面简约示例更清晰些)。这里有个问题,就是赋值的等号左右两侧维度不一样,以上面打印的10行数据为例,等号左侧
temp_df.loc[temp_df['temp_name_zt_{}'.format(i)] == val, 'qg_zt_{}'.format(i)]取出值为zt_1a的Series只有2个元素,而等号右侧temp_df[val]取出的是1列数据,有10个元素,这里赋值是会根据索引进行对应赋值,即对索引1085和1086对应的元素进行赋值。来看一下qg_zt_X的结果:
date qg_zt_0 qg_zt_1 qg_zt_2 ... qg_zt_6 qg_zt_7 qg_zt_8 qg_zt_9
1080 2021-09-09 False True False ... False False False False
1081 2021-09-10 False True False ... False False False False
1082 2021-09-13 False True False ... False False False False
1083 2021-09-14 False True False ... False False False False
1084 2021-09-15 False True False ... False False False False
1085 2021-09-16 True False True ... False False False False
1086 2021-09-17 False True False ... False False False False
1087 2021-09-22 False True False ... False False False False
1088 2021-09-23 False True False ... False False False False
1089 2021-09-24 False True False ... False False False False
对应的qg_zt_X均已根据列名转化为对应的布尔值,表示前期高点前的各天是否是涨停。
- 第8行,列名列表,用于统计涨停的次数。
- 第9行,统计涨停的次数,结果保存在qg_zt_num列中。
看一下计算结果:
date open high low ... zt xg qg_jl qg_zt_num
1080 2021-09-09 40.00 40.36 38.06 ... False False 19 1
1081 2021-09-10 38.79 40.00 38.30 ... False False 20 1
1082 2021-09-13 41.00 43.76 39.91 ... True False 21 1
1083 2021-09-14 44.68 46.80 42.92 ... False False 22 1
1084 2021-09-15 45.70 49.96 44.00 ... True True 23 1
1085 2021-09-16 52.31 53.46 45.87 ... False True 1 2
1086 2021-09-17 46.20 46.73 44.00 ... False False 1 2
1087 2021-09-22 45.03 46.37 43.50 ... False False 2 2
1088 2021-09-23 45.18 48.73 43.92 ... True False 3 2
1089 2021-09-24 48.65 53.60 47.10 ... False True 4 2
对照上文中的K线图:
- 9月15日,前高在23个交易日前,即8月13日,8月13日(包含)的前10个交易日内,有1次涨停(8月12日)。
- 9月24日,前高在4个交易日前,即9月16日,9月16日(包含)的前10个交易日内,有2次涨停(9月15日、9月13日)。
至此完成了DataFrame按列内容取不同列的值生成新列。
简约示例
上文的例子过于复杂,下面用一个简单的例子进行说明。
首先构造一个简单的DataFrame:
df = pd.DataFrame([[1, 2, 3, 'A'],
[4, 5, 6, 'C'],
[7, 8, 9, 'B']], columns=['A', 'B', 'C', 'D'])
print(df)
A B C D
0 1 2 3 A
1 4 5 6 C
2 7 8 9 B
其中,D列存放了不同的列名,我们要求新建一列E,来保存各行按D列内容获取对应列中的内容。例如,第0行第D列的值为A,那么我们希望第0行第E列的值等于第0行第A列的值(1);第1行第D列的值为C,那么我们希望第1行第列E的值等于第1行第C列的值(6);第2行第D列的值为B,那么我们希望第2行第E列的值等于第2行第B列的值(8);也就是说,我们的目标是生成下面的数据:
A B C D E
0 1 2 3 A 1
1 4 5 6 C 6
2 7 8 9 B 8
实现代码如下:
df['E'] = None
for val in df['D'].unique():
df.loc[val == df['D'], 'E'] = df[val]
- 第1行,新建列E,赋值为None。如果没有这一步,会导致由于局部赋值,新列结果都为浮点型的情况。
-
2~3行,循环对E列赋值。等号左侧
df.loc[val == df['D'], 'E']类型为Series,取出的是所有D列值为val的行的E列;等号右侧df[val]类型也是Series,提取的是列名为val的列。以val=B为例,
df.loc[val == df['D'], 'E']取出的是有D列值为B的行的E列,打印结果如下:
print(df.loc[val == df['D'], 'E'])
2 None
Name: E, dtype: object
而df[val]取出的是B列:
print(df[val])
B
0 2
1 5
2 8
Name: B, dtype: int64
可以看到等号两侧Series所包含的元素个数不同,但并不影响赋值操作,赋值会按照索引进行对应赋值,即把等号右侧索引为2的值8,赋值给等号左侧索引为2的元素。
经过测试,生成的新列E符合预期。
小结
本文结合股票因子计算的实例以及一个简约示例,展示了DataFrame按列内容取不同列的值生成新列的过程。这是目前笔者找到一种解决方案,如果读者有更好更快的方案,也请留言交流。

df[‘E’]=None
for i in range(len(df)):
df.iloc[i,-1]=df.loc[i,df.iloc[i,-2]]